
在先前,我們成功地運用 Prometheus 進行 Kubernetes 叢集的基本 APM 監控,這無疑是一個很棒的第一步。但當 Prometheus 的監控指出某個服務的 CPU 和記憶體使用率驟增,甚至該服務不斷重新啟動時,我們的第一反應通常是查詢日誌以了解是否存在異常。此情境突顯了,除了監控工具外,日誌可能是最能協助我們了解服務間互動的可觀測性工具。
在接下來的章節中,我們將深入探討 Grafana 團隊為我們提供的日誌解決方案 Grafana Loki 的基礎概念與架構。

在很早之前,Grafana 團隊發現很多人都跟他們一樣認為當今社群上,沒有一套足夠穩定且費用低廉的日誌工具,甚至吹起一股減少日誌量的反模式的聲音,而 Grafana 團隊開始有幾個對日誌的想法出現:
而這些社群上對日誌的需求,催生了 Grafana Loki 的誕生。
Loki 於 2018 年 12 月在北美的 KubeCon 上推出,是一款由 Grafana 團隊開源的高度可擴展、高可用且支持多租戶的日誌聚合系統。該系統主要旨在處理分布式大型系統中的大量日誌問題。Loki 不僅擁有分佈式架構,還與 Prometheus 和 Grafana 緊密結合,使其能迅速處理大量的日誌數據。此項目受到 Prometheus 的啟發,其官方定義為:“Like Prometheus, But For Logs”。
與其他日誌聚合系統相較,Loki展現出以下特點:
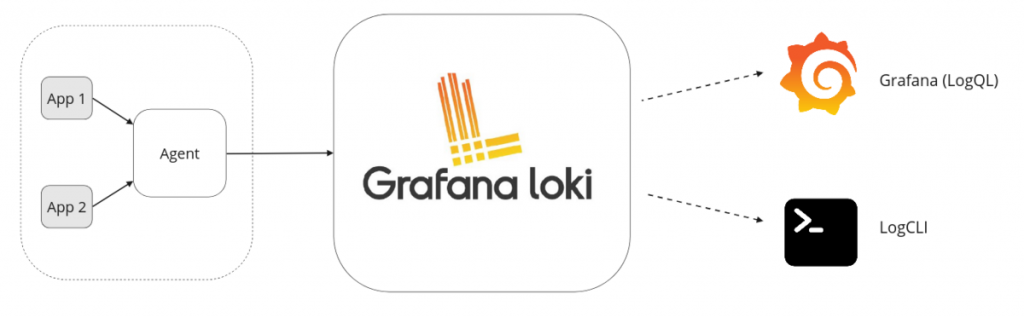
Loki是不僅具有上面提到的技術優勢,還為組織帶來了許多不容忽視的好處。以下是使用 Loki 的主要理由:
總之,Loki 的優點還是顯而易見,它是一款快速、成本效益高、高度可擴展的日誌工具,能夠與 Prometheus 標籤無縫整合,並允許用戶在指標和日誌之間輕鬆切換。
相信很多人會好奇 Loki 與另一個常被拿來做日誌工具 Elasticsearch 的各種比較,剛好小弟正好在工作內容上的一部份是在處理 Elastricsearch 轉移到 Grafana Loki 的遷移工程,由於三十天的篇幅不太夠,如果有興趣的話的同學也可以敲碗讓我知道。
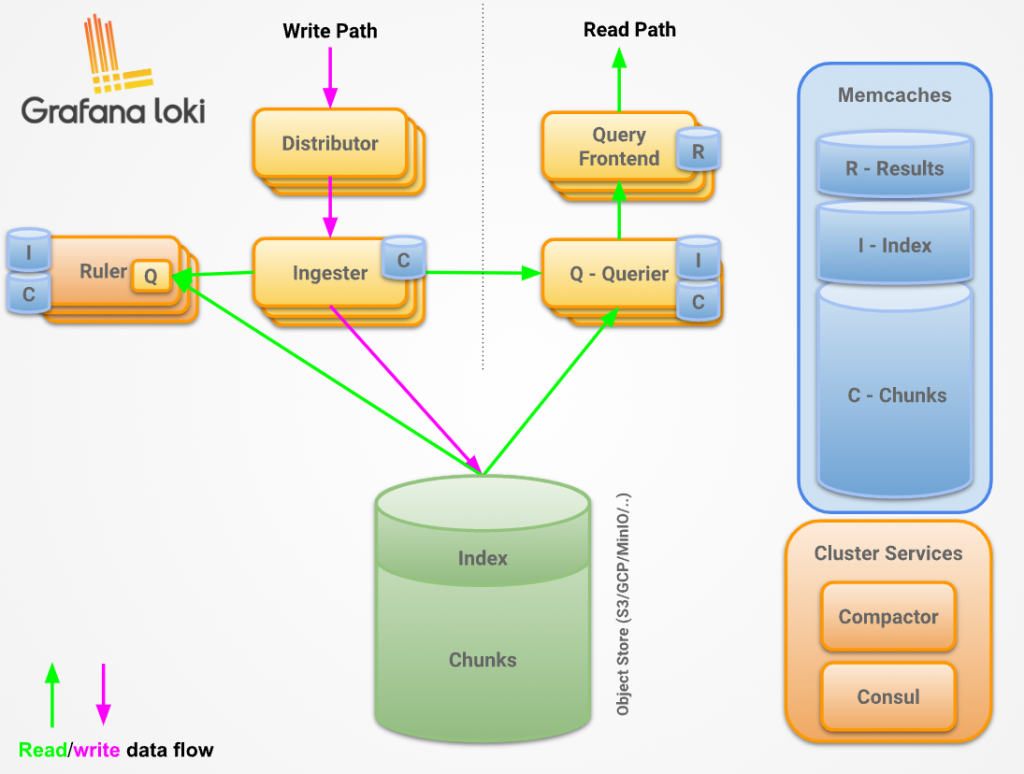
Distributor 是負責處理客戶端傳入的數據流的服務。它是寫入日誌數據的第一站。當分發器接收到一組數據流時,每個流都會進行正確性驗證,並確保其在配置的租戶(或全局)限制內。然後,有效的數據片段被拆分成批次並平行發送到多個 Ingesters。
放置一個負載均衡器在 Distributor 前面是很重要的,以確保正確平衡流量。
分發器是一個無狀態的組件,這使得它易於擴展,並從寫入路徑上的最關鍵組件 Ingesters 中卸載盡可能多的工作,並且帶有各種預處理、速率限制的作用,獨立地擴展這些驗證操作的能力意味著 Loki 也可以保護自己不受拒絕服務攻擊,否則可能會使 Ingesters 超載。Distributor 就像在前門的保鑣,確保每個人都穿著得體且有邀請函。這也允許我們根據我們的複制因子擴展寫操作。
以上提到的細節如下:
Ingester 是Loki系統中的核心組件,其主要職責是在寫路徑中將日誌數據寫入長期存儲後端(如 DynamoDB, S3, GCS 等)並在讀路徑上為內存查詢返回日誌數據。
在 Ingester 還有幾個重要細節如下:
日誌流與塊:
接收的每個日誌流都會在內存中形成多個“塊”。
在可配置的時間間隔後,這些“塊”會被刷新到後端存儲。
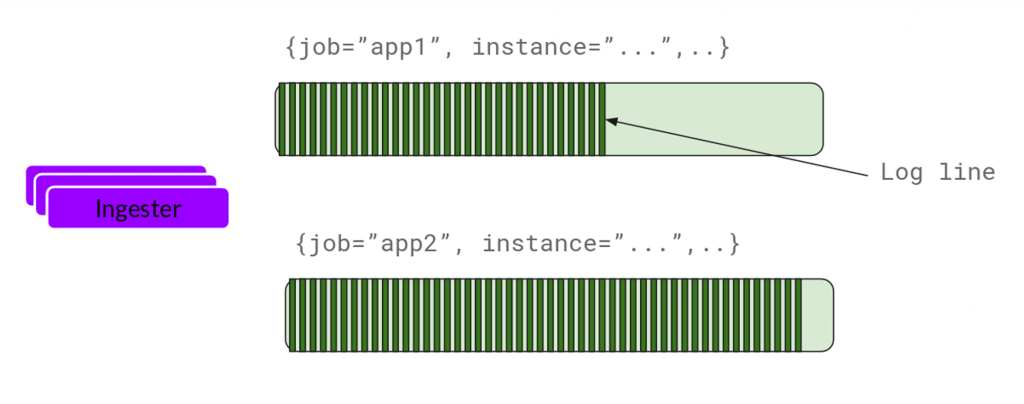
塊的壓縮與只讀標記:
當達到容量、超時或發生刷新操作時,當前塊被壓縮且標記為只讀。
壓縮的塊被新的可寫塊替代。

數據安全性:
哈希與去重:
時間戳排序:
Compactor 在 Loki 系統中扮演著關鍵角色,主要負責索引的去重、數據去重及保留工作。它不僅提高了存儲效率,還為使用者提供了一個更加整潔和有效的查詢體驗。
通過Compactor,Loki 系統確保了高效的存儲使用和流暢的查詢體驗,並且確保在配置或操作上的任何失誤不會對數據造成無法修復的損害。
注意:一次只能運行 1 個壓縮器實例,否則可能會產生問題並可能導致數據丟失。
Query frontend 在確保查詢效率和系統的穩定性上起著至關重要的作用。以下是主要功能:
Querier 負責解讀和執行使用者基於 LogQL 查詢語言的查詢要求,其工作不僅包括從寫入緩存的 Ingester 提取日誌,還涉及從長期存儲中提取資料。
以下是其工作流程及核心功能的概述:
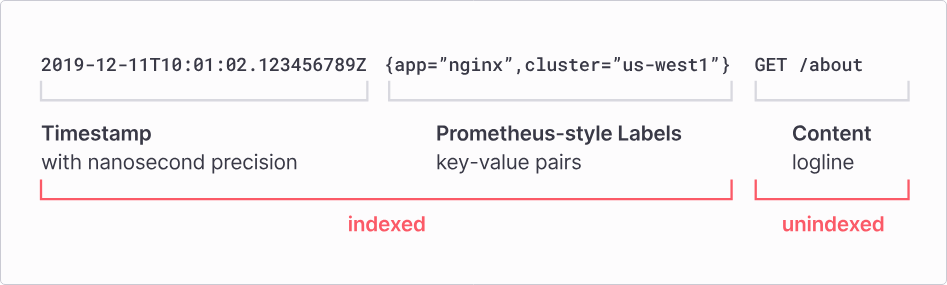
Grafana Loki 區別於其他日誌系統,其核心概念是只索引有關日誌的標籤集,與 Prometheus 標籤相似。而日誌數據則被壓縮並存儲在如S3或GCS的對象存儲中,或者直接在本地文件系統上。然而,日誌數據本身被儲存分成「索引(index)」以及「塊(chunk)」兩部份儲存,兩者可以被儲存於對象存儲服務(如 GCS、S3)中,甚至是存儲在本地文件系統(filesystem)中。不論如何,輕量索引加上高度壓縮的塊簡化了操作並且顯著降低了 Loki 的成本。
在 Loki 2.0 之前,塊跟索引數據需要各自存儲在單獨的後端中,索引就存在 Nosql / Key-Value 數據庫而塊儲存在對象存儲服務或文件系統。在 Loki 2.0 帶來了一個名為「boltdb-shipper」的索引機制,這被稱為 Single Store,僅需一個對象存儲即可存放索引和數據塊,大大的減少 Loki 本身對其他服務的依賴。而在 Loki 2.7 引入實驗性質的 TSDB 模式,在 Loki 2.8 之後取代 boltdb-shipper 正式成為 Loki 推薦的持久儲存模式。
TSDB 僅僅在兩個小版本就取代 boltdb-shipper,受益於 Prometheus 對於 TSDB 社群大規模成熟使用經驗,使其的可以同時實現減少存儲成本並提升查詢效能的作用。在後面我們將搶先體驗 TSDB 實戰,有機會的話,我們還可以深入探討 TSDB 在哪個地方彌補的 boltdb-shipper 的不足。
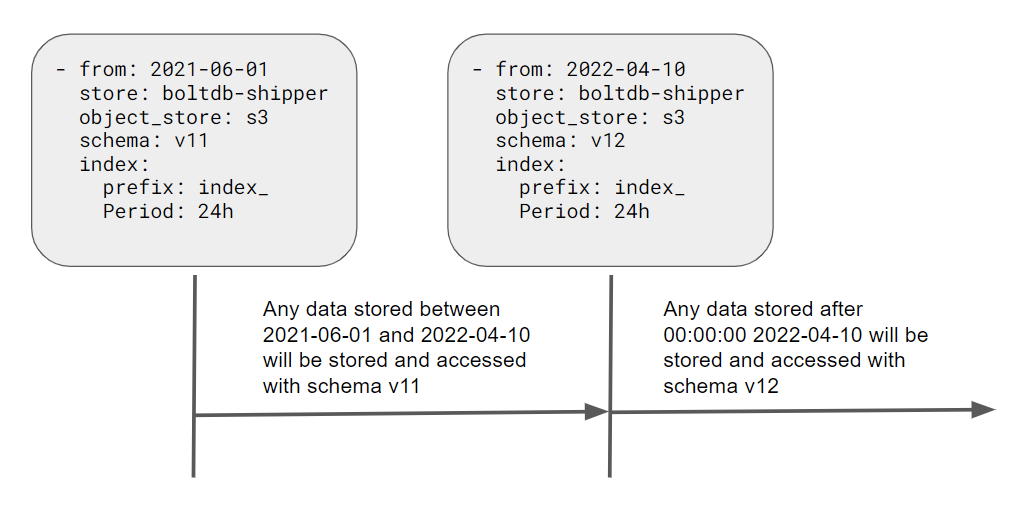
Loki 的目標是實現向後兼容,保留在其內部進行開發的空間,並且開放促進更好、更高效的存儲開發,所以 Loki 允許我們迭代升級到這些新的存儲模式,並起可以在底層無感切換使用,這使升級底層存儲模式這類的大工程變成輕而易舉。例如上圖表示:從 2021 年 6 月 1 號後的區間使用 v11 版本存儲格式,但 2022 年 4 月 10 號之後使用 v12 版本存儲格式。
Loki Canary 是一個獨立的應用服務,用於審核 Grafana Loki 集群的日誌捕獲性能。Canary 服務將會生成日誌像 Loki 叢集正常發送,並且另以 Websocket 與 Loki 叢集通訊,以便形成有關叢集性能的資訊。
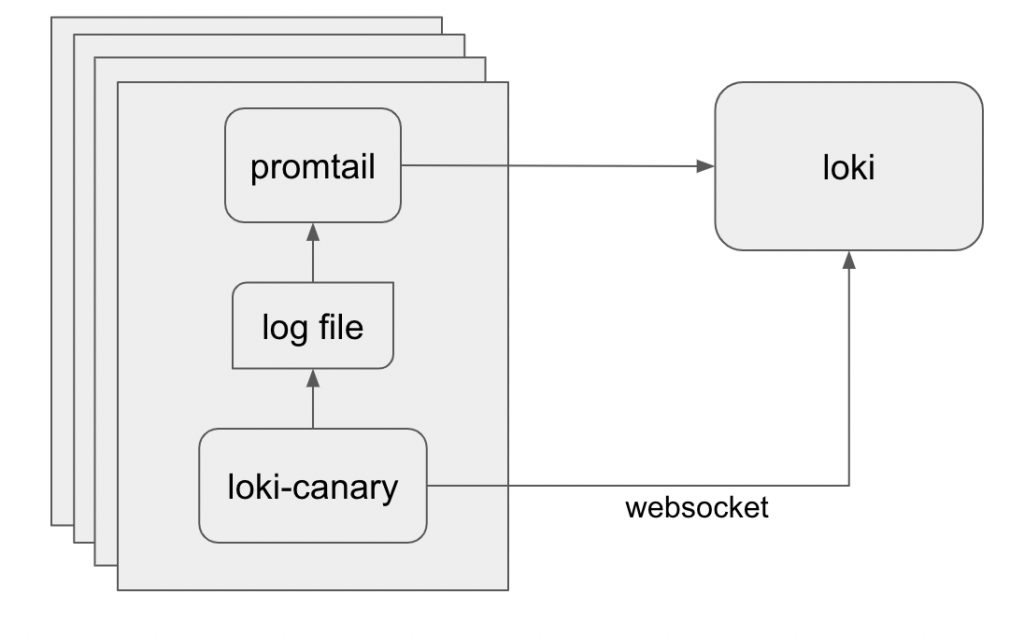
Canary 運作相當簡單,可以配置時間間隔和可配置的大小寫入日誌,這些日誌由 promtail 讀取並發送到 Loki。同時,Canary 打開與 Loki 的 Websocket 連接,並為其寫入的日誌提供即時的 tail 日誌。Canary 生成一系列指標,然後將其抓取並由 Prometheus 發出警報。這些指標包括丟失、無序或重複的任何日誌的計數器。此外,通過比較金絲雀放入日誌中的時間戳,而 Grafana 團隊還創建了從創建日誌到通過 Websocket 接收日誌的響應時間的直方圖。
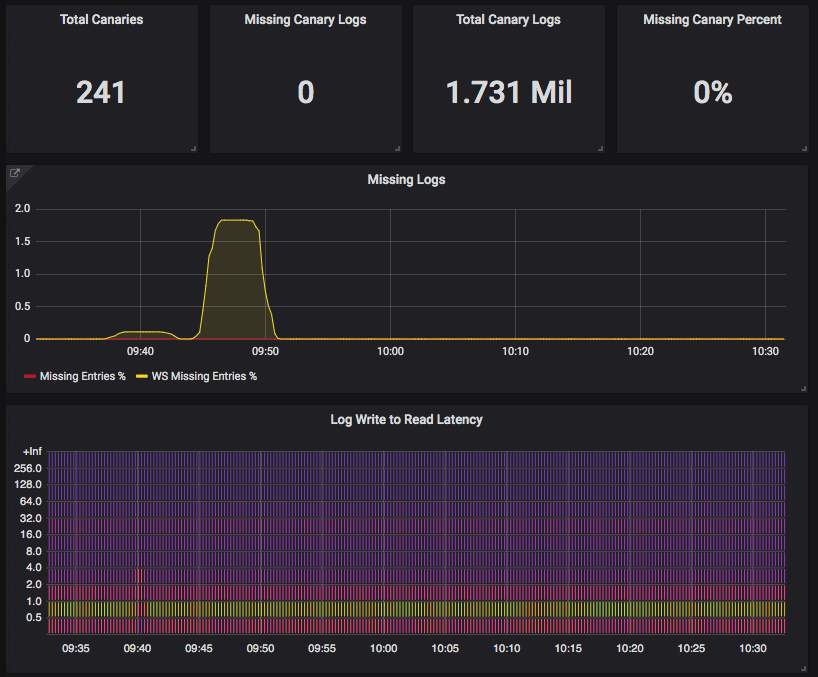
上圖顯示 Loki 在 9:40 左右執行部署,導致延遲略有增加,並且 Websocket 連接上丟失了一些日誌。然而,對丟失日誌在經過後續查詢證實它們實際上安全地存儲在 Loki 中,並且在部署過程中沒有丟失任何日誌!
Grafana Loki 是一個擁有多租戶功能的系統,其中租戶 A 的請求和數據與租戶 B 可以是隔離的。如果我們在 Grafana 中需要特別指定租戶 ID 才能 M 向 Loki API 的請求,因為開啟多組戶功能後,每個請求需要包含一個 HTTP Header「X-Scope-OrgID」以識別該請求的租戶。
當配置為 auth_enabled: false 時,Loki使用單一租戶,並且在Loki API請求中不需要「X-Scope-OrgID」作為 Header 值。單一租戶的ID將是字符串fake。
在本篇文章中,我們將深入探討 Grafana Loki 及其組件和核心概念。Loki 在 Tempo、Mimir 系統中是最為穩定和成熟的,其內部蘊含著豐富且值得深入討論的細節。由於 Grafana 的官方文件以其簡約而聞名,許多資料過於零碎發散,需要不斷的廣泛搜尋拼湊,在撰寫本文時我嘗試以最合理的順序,精練地介紹 Loki 的關鍵觀念。其他更細緻的部分,也許我們將在實戰演練中探討,或可能在進行效能調校時一同探索。下面,現在就讓我們進入實戰演練,親身體驗 Grafana Loki 的強大吧。
相關程式碼同步收錄在:
https://github.com/MikeHsu0618/grafana-stack-in-kubernetes/tree/main/day22
References
Loki’s Path to GA: Loki-Canary Early Detection for Missing Logs | Grafana Labs
Loki Canary | Grafana Loki documentation
Grafana Loki Storage | Grafana Loki documentation
Grafana 系列文章(十):为什么应该使用 Loki - 掘金
Grafana, Loki, and Tempo will be relicensed to AGPLv3 | Grafana Labs
Multi-tenancy | Grafana Loki documentation
How to run faster Loki metric queries with more accurate results | Grafana Labs
Watch: 5 tips for improving Grafana Loki query performance | Grafana Labs
10 things you didn’t know about LogQL | Grafana Labs
Grafana 系列文章(九):开源云原生日志解决方案 Loki 简介 - 掘金
[DevOps]Grafana + Loki + Promtail Logging system 小試牛刀
